

I'm going to talk about another String matching algorithm. This is a more efficient way to do the String searching when we compare with brute force algorithm(Naive).
This algorithm is conceived 1970 by Donald Knuth and Vaughan Pratt.that's why this called as
Knuth–Morris–Pratt algorithm(KMP) . different of this algorithm is it keeps track of information from last comparison.if m is the length of pattern and n is length of text we searching, this algorithm is running with O(m+n) time complexity.
To learn this algorithm first you should know about prefix and suffix in a word. To get a basic idea about that.Refer to picture i mentions below.

lets talk about this algorithm.now we should create a table of prefix function according to a given pattern.i will explain through an example.
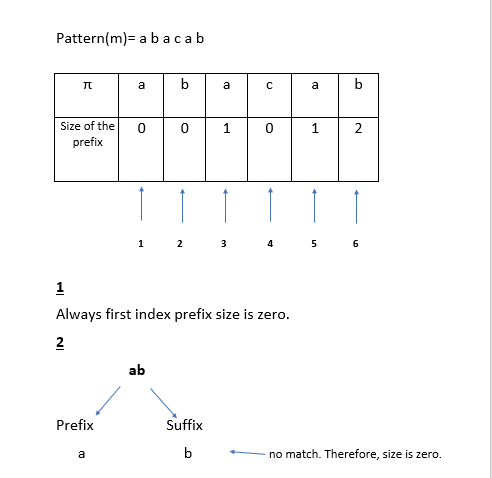
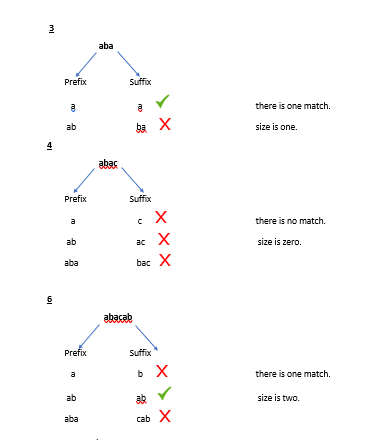
after finish that table we can move to the algorithm.
//CODE
//KMP Method
//Prefix finding function
public static int[] preFixFn(String p) {
int m=p.length();
int k=0;
int [] PI=new int[m];
PI[0]=0;
char[] P=p.toCharArray();
for(int q=1;q<m;q++) {
do{
k=PI[k];
}while(k>0 && (P[k]!=P[q]));
if(P[k]==P[q]) {
k++;
}
PI[q]=k;
}
return PI;
}
public static String KMP(String t,String p) {
int n=t.length();
int m=p.length();
int q=0;
int[] PI= new int[m];
PI=preFixFn(p);
//Print Prefix Function
System.out.print("[Prefix Function:");
for(int j=0;j<PI.length;j++) {
System.out.print(PI[j]);
}
System.out.print("]");
char[] T=t.toCharArray();
char[] P=p.toCharArray();
for(int i=0;i<n;i++) {
while(q>0 && (P[q]!=T[i])) {
q=PI[q];
}
if(P[q]==T[i]) {
q++;
}
if(q==m) {
return "Pattern "+p+" found at "+Integer.toString(i-m+1)+" index of text "+t+" using KMP method";
}
}
return "Pattern not found";
}




1 Comments
Wpresesmesn Wendy Young https://www.crosca.com/profile/jardinewalmenulricka/profile
ReplyDeletejoisturellei
Thanks for the feedback